Groq: A Lightning Fast AI Platform for Large Language Models
If you are looking for a way to run large language models (LLMs) with blazing speed and low latency, you might want to check out Groq.
Groq is a company founded by ex-Google engineers who worked on the first Tensor Processing Unit (TPU) chip for machine learning.
They left Google in 2016 to create a new kind of AI chip that is optimized for LLMs, such as GPT-4, Gemini, and Grok.
Groq’s chip is called the Tensor Streaming Processor (TSP), and it is classified as a Language Processing Unit (LPU), not a Graphics Processing Unit (GPU).
How is Groq different from other AI chips
Groq’s LPU is designed to overcome two major challenges that LLMs face: compute density and memory bandwidth.
LLMs require a lot of computation and memory to process large amounts of data and generate coherent text.
GPUs and CPUs, which are general-purpose chips, can do a lot of things, but they also have limitations in terms of performance and latency.
Groq’s LPU, on the other hand, is custom-built for a specific task: dealing with sequences of data in LLMs.
It has a minimalist yet high-performance architecture that eliminates the need for complex scheduling hardware and favors a more streamlined approach to processing.
Benefits of using Groq
Groq’s LPU offers several benefits for LLM users, such as:
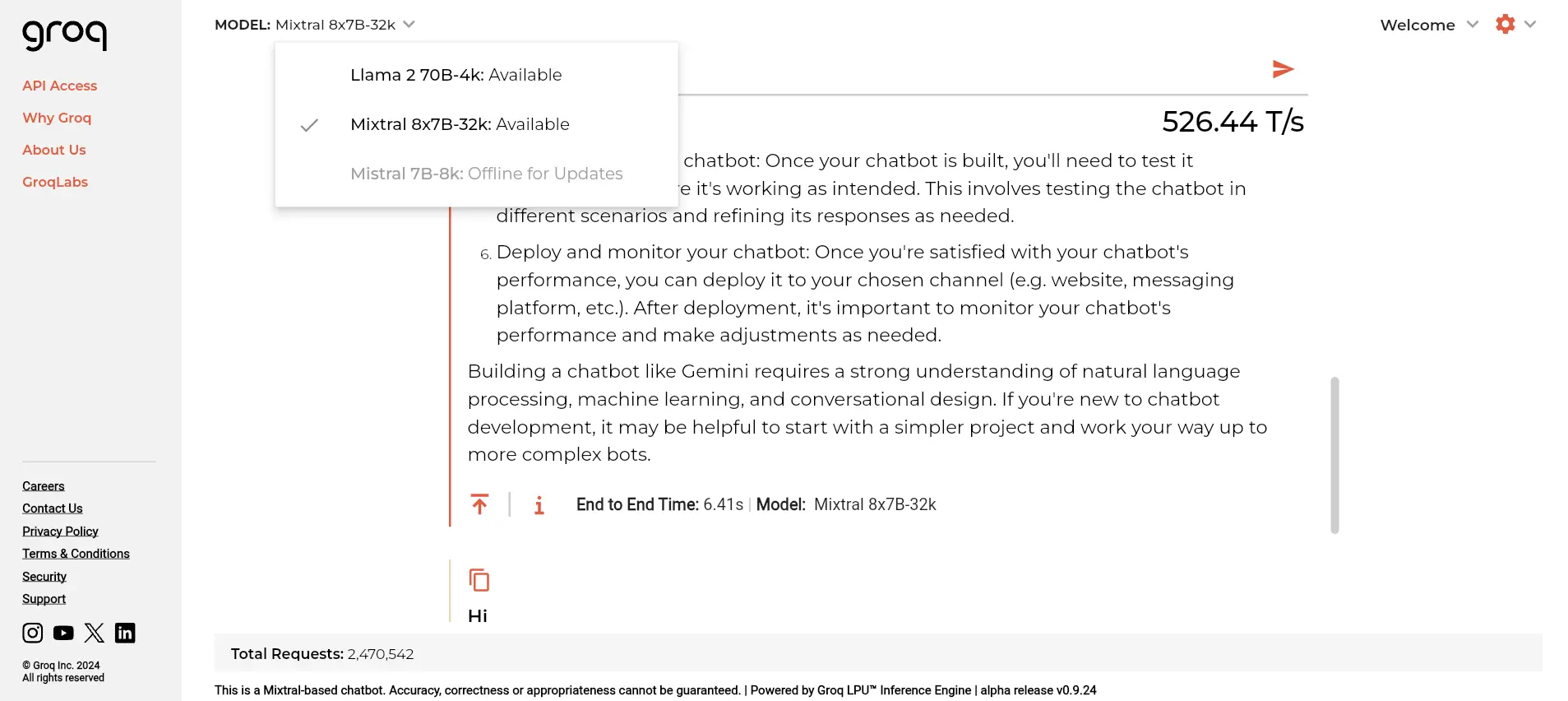
- Faster text generation: Groq’s LPU can generate up to 500 tokens per second when running a 7B model, and up to 250 tokens per second when running a 70B model. This is much faster than Nvidia’s GPUs, which offer around 30 to 60 tokens per second. This means you can get more output in less time and with more accuracy and consistency.
- Lower latency: Groq’s LPU has a deterministic performance, which means it delivers the same output at the same speed every time, regardless of the input size or complexity. This reduces the delay between the input and the output and improves the user experience. For example, voice assistants based on LLMs, such as ChatGPT’s Voice Chat feature or Gemini AI, which replaced Google Assistant on Android phones, can respond faster and more naturally with Groq’s LPU.
- Minimum energy consumption: Groq’s LPU is more energy-efficient than Nvidia’s GPUs, as it consumes less power and generates less heat. This makes it more suitable for edge devices, such as smartphones, tablets, and laptops, where battery life and thermal management are important factors.
How can I use Groq
Groq’s LPU is not an AI chatbot, and it is not meant to replace one. Instead, it is meant to make them run faster and more efficiently.
Groq’s LPU supports standard machine learning frameworks, such as PyTorch, TensorFlow, and ONNX, for inference.
However, it does not currently support machine learning training. You can use Groq’s LPU with open-source LLMs, such as Llama-2 or Mixtral 8x7B, or with your own custom models.
You can also access Groq’s LPU through its cloud service, which offers a simple and flexible API.
Why should I choose Groq
Groq is challenging the established players, such as Nvidia, and shaping the future of AI technology.
Groq’s LPU is a game-changer for LLM users, as it provides faster and more efficient processing, with lower latency and consistent throughput.
Groq’s LPU is ideal for applications that require real-time text generation and natural language processing, such as chatbots, voice assistants, content creation, and more.
If you want to take your LLMs to the next level, you should give Groq a try.